
LlamaIndex - Use the Power of LLMs on Your Data
Everyone has been talking about Large Language Models (LLMs). ChatGPT shows the power of this phenomenal technology in an impressive way. LLMs are pre-trained on a large amount of data. We can use it for our data.

But how we best augment LLMs with our data?
In this case, we need a toolkit to help us. LlamaIndex (previous GPT-Index) is a good fit for this. It’s a simple and flexible data framework that helps you to connect your data to LLMs. You can connect your unstructured, structured, or semi-structured data sources.

We’ll discuss the following points in this article:
- Ingesting your data
- Indexing your data
- Query over your data
Sneak Peek
Do you want to know what to expect in this article? For this tutorial, we use a PDF file of our article “The Future of Artificial Intelligence is Open-source! Here’s Why?”. Below you can see a preview.
Prompt: Summarise the article in one sentence.
Output:
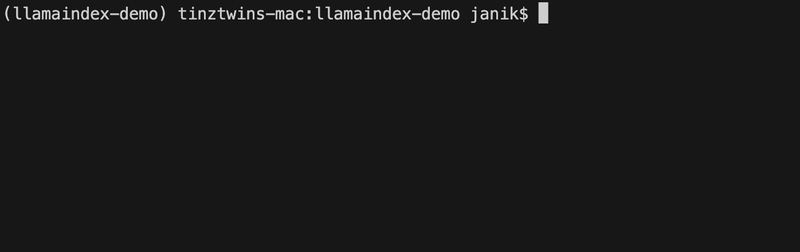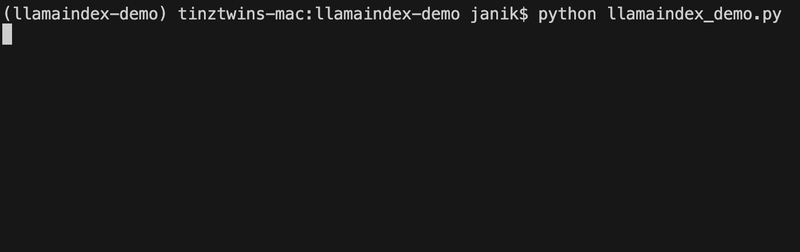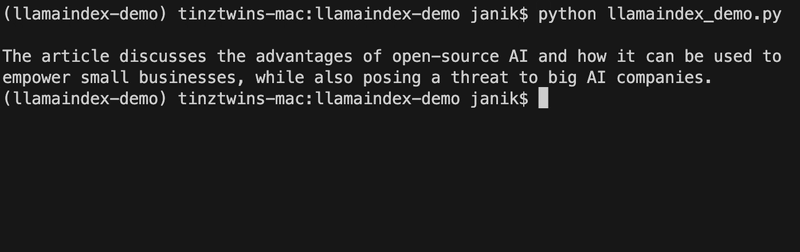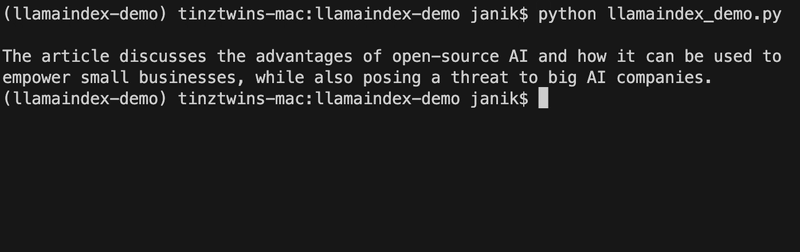
Great summary! We created this example with five lines of code. Impressive! Do you want to learn more about LLamaIndex and how to create an example like this? In our article, we give you a beginner-friendly introduction to LlamaIndex.
What is LlamaIndex?
With LlamaIndex, you can connect your custom data sources to LLMs. The framework is very user-friendly. There is a high-level API for beginners and a low-level API for the advanced user. In this tutorial, we’ll focus on the high-level API. In addition, the framework allows you to build powerful end-user applications. You can integrate LlamaIndex easily into your existing tech stack (e.g., LangChain, Flask, Docker, or anything else). A brief overview of possible use cases:
- Document Q&A: Ask questions about your documents and get answers (e.g., PDFs, Images, etc.).
- Data Augmented Chatbots: Chat with your data.
- Knowledge Agents: Index your knowledge base and build an automated decision machine.
- Structured Data Warehouse Analytics: Query your data warehouse with natural language.
The LlamaIndex data framework is popular on GitHub. Look at the stars over the last months.
Let’s not waste time. We jump straight into the practical part.

Technical requirements
Prerequisites
You’ll need the following prerequisites:
- Installed Python
- Installed conda and pip
- Access to a bash (macOS, Linux, or Windows)
- Code editor of your choice (We use VSCode for Mac.)

Create a Q&A service for your documents
First, we created a folder named llamaindex-demo. In this folder, we create a second folder with the name data. The data folder contains our documents. In our case, we put our PDF file there.
1. Step — Create a virtual environment with conda
Enter the following in your terminal:
- Create a conda environment (env):
conda create -n llamaindex-demo python=3.9.12-> Answer the question Proceed ([y]/n)? with y. - Activate the conda env:
conda activate llamaindex-demo
2. Step — Set OpenAI API Key
By default, LlamaIndex uses the OpenAI GPT-3 text-davinci-003 model. To use this model, you must have an API Key. Do you have an API Key yet? If not, no problem. You can generate an OpenAI API Key in your OpenAI Account. Log in or Sign up to OpenAI and create your API Key.

Click “Create new secret key” and give your key a name. After your API Key is generated, you can save the key. Be careful the key is only displayed once!
All right. Next, we must set the API Key as an environment variable. Execute the following command in your terminal:
# macOS and linux
$ export OPENAI_API_KEY=[Insert your API Key here.]
# windows
$ set OPENAI_API_KEY=[Insert your API Key here.]
3. Step — Install dependencies
Now, we install all required Python packages. Make sure you are in the virtual conda environment.
pip install llama-index pypdf
Python Packages:
-
llama-index: LlamaIndex is a data framework for your LLM apps. -
pypdf: pypdf is a free and open-source pure-python pdf library. We need this package, because we use a PDF file as an input document.
4. Step — Load documents
Next, we create a Python file for our LlamaIndex Demo Project. Copy the following Python Code into this file.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
With the function load_data(), we load the data from our data folder. LlamaIndex provides a wide range of data loaders. The data is represented as Document objects. A Document is a lightweight container.
5. Step — Indexing
Now, we can build an index over the document objects. In this tutorial, we use the simple high-level abstraction to load the document objects for indexing.
from llama_index import VectorStoreIndex
index = VectorStoreIndex.from_documents(documents)
For this process, we only need one line of code. We import VectorStoreIndex and use the .from_documents() to load the document objects. That’s it. We created an index.
6. Step — Query the index
In the last step, we query the index with a QueryEngine. A query is simply an input to an LLM. We use the index for question-answering. In the following code snippet, you see how to create a query engine with default configs.
query_engine = index.as_query_engine()
Further information, can find in the documentation.
Example 1:
response = query_engine.query("What is GPT4All?")
print(response)
Response: GPT4All is a model and an ecosystem created by Nomic. It is a collection of different LLMs (Language Modeling Machines) that can be used in Python projects. It can also be used like ChatGPT, a chatbot, on computers with installers for Windows, macOS, and Ubuntu. GPT4All is free-to-use, locally running, and privacy-aware. It does not require a GPU or internet connection.
The response contains all the facts of our article. However, a small mistake has crept in. LLMs are the abbreviation for Large Language Models, not Language Modeling Machines.
Example 2:
response = query_engine.query("When was GPT4All created?")
print(response)
Response: March 25, 2023
The response is correct.
Example 3:
response = query_engine.query("What is the opinion of the authors? Please cite.")
print(response)
Response: The authors’ opinion is that open-source AI is becoming more powerful and can be integrated into products for free, without data privacy problems or dependence on big companies. They believe that the swarm intelligence of the open-source community is the biggest threat to big AI companies, and that big companies should disclose the essential things around AI because AI concerns us all. They also suggest that entrepreneurs should take advantage of open-source AI. Cite: “Open Source AI empowers small businesses.” (by the authors)
The third example also gives a good result. The response contains the main information of our article.
Conclusion
The power of the LlamaIndex data framework is impressive. You only need five lines of code to create a Q&A service for your data. You learned how to use the high-level API of LlamaIndex to load documents, index documents, and query the index. The examples have shown that the response is clear and mostly right. We must remember that we have only used the default settings. With the help of the low-level API, we could improve the responses.
Thanks so much for reading. Have a great day!




